html过滤指定标签以及属性css样式
一辈子都要和别人去比较,是人生悲剧的源头
1 |
|
一辈子都要和别人去比较,是人生悲剧的源头
1 |
|
人生若只如初见,何事秋风悲画扇
1 | SELECT * FROM user WHERE name` != '冰峰'; |
我们给name字段建立了索引,但是如果!= 或者 <> 这种都会导致索引失效,进行全表扫描,所以如果数据量大的话,谨慎使用
1 | SELECT * FROM user` WHERE height= 175; |
height表字段类型是varchar,但是我查询的时候使用了数字类型,因为这个中间存在一个隐式的类型转换,所以就会导致索引失效,进行全表扫描。
1 | SELECT * FROM user` WHERE DATE(create_time) = '2020-09-03'; |
如果你的索引字段使用了索引,对不起,他是真的不走索引的
1 | SELECT * FROM user` WHERE age - 1 = 20; |
1 | SELECT * FROM user WHERE name` = '张三' OR height = '175'; |
OR导致索引是在特定情况下的,并不是所有的OR都是使索引失效,如果OR连接的是同一个字段,那么索引不会失效,反之索引失效。
1 | SELECT s.* FROM user s WHERE NOT EXISTS (SELECT * FROM user u WHERE u.name = s.name AND u.name` = '冰峰') |
这两种用法,也将使索引失效。但是NOT IN 还是走索引的,千万不要误解为 IN 全部是不走索引的。
被门夹过的核桃还能补脑嘛
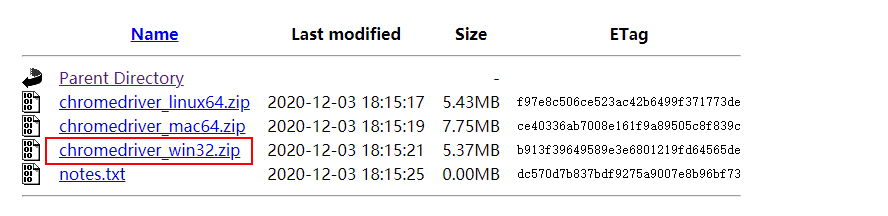
下载地址: http://chromedriver.storage.googleapis.com/index.html
更高版本: https://googlechromelabs.github.io/chrome-for-testing/
注意: chrome版本必须和chromedriver版本相同,如果没有一模一样的版本,选择能包括它的版本即可
chrome版本的查看方式,打开地址chrome://settings/help即可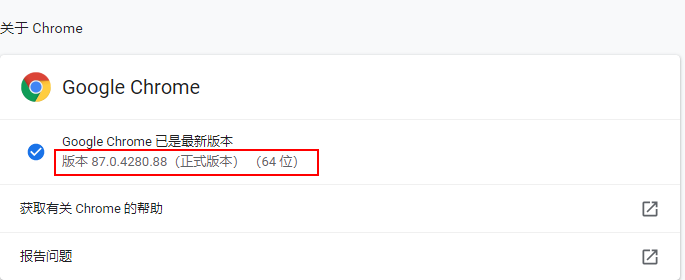
将下载后的文件解压chromedriver.exe放到目录C:\Program Files\bin下,并记下这个目录,理论上可以放到本地的任何位置,全凭个人喜好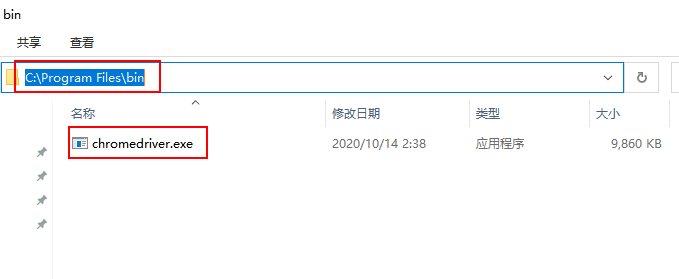
将存放chromedriver.exe的目录添加到环境变量中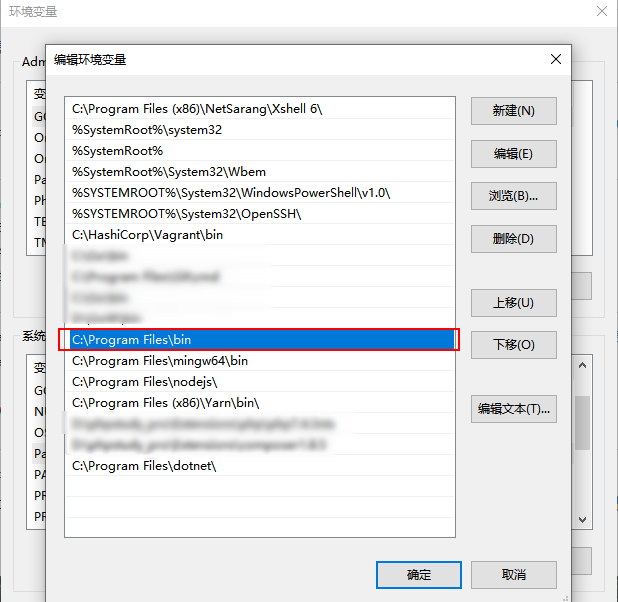
使用win+r快捷键调出 运行窗口, 并输入cmd 命令, 打开cmd窗口, 在窗口中输入chromedriver,是否能够正确显示版本号, 如不生效,可以尝试重启计算机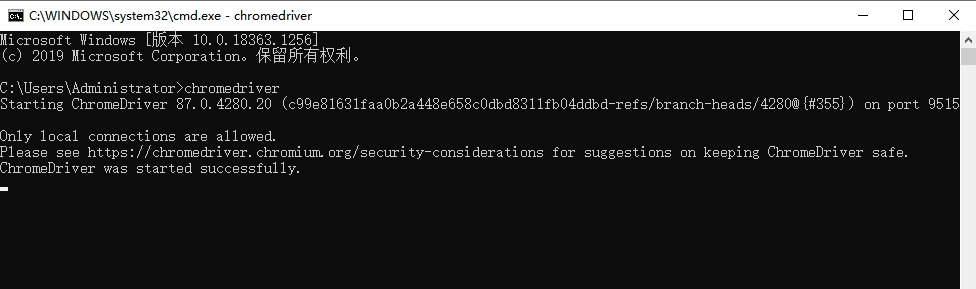
所谓的光辉岁月,并不是以后,闪耀的日子,而是无人问津时,你对梦想的偏执。
PHP-FPM 提供一个叫 慢日志 (slowlog) 的功能,来帮助我们定位执行慢的脚本。
以 PHP 7.2 为例,FPM 的配置信息位于:
1 | /etc/php/7.2/fpm/pool.d/www.conf |
相关配置项:
1 | ; 慢日志的存储路径,默认 `$pool` 设置为 `www` |
以上的配置翻译过来:指定 FPM 当发现有请求执行超过 1 秒钟的时候,将整个调用堆栈记录到 /var/log/www.slow.log 文件里,堆栈的深度不超过 20。
你可以把 1s 改成其他值,如 10s。有了以上的设置,裁剪图像尺寸的方法、 网络 I/O 相关的一些请求都经常出现在 PHP 慢日志中。你可以根据自己的情况来选择调整或者忽略。
开启了慢日志,网站运行一段时间后,如果记录了较多的慢日志,如何进行有效分析?
可以使用 grep 命令来快速定位某个函数调用、或者脚本名称被记录的次数,记录的次数越多,优化的优先级就越高。以下是简单的 示例:
1 | $ grep -o 'fetch_github_user' /var/log/www.slow.log | wc -l |
慢日志可以帮助我们定位到运用程序里的瓶颈,是一个非常好用的工具,也是每个 PHP 开发者都需要知道的工具。
需要注意的是,监控 Slowlog 和记录日志的过程会对 PHP 造成消耗, 切记 调试结束后,务必将其关闭。
你那能叫活着么?你那只能叫没死。
因为CDN的存在,所以SSL需要分为两部分,一部分是浏览器到Cloudflare CDN服务器的传输加密,一部分是Cloudflare CDN服务器到你网站服务器之间的数据传输。一般来说,如果选择Off,那你的网站全程都没有SSL加密,如果选择Flexible,那么Cloudflare CDN服务器到你网站服务器之间是明文传输,有可能存在一定的被监听风险,如果选择Full,则全程都是用SSL加密,但是并不校验网站服务器的证书有效性(所以当被中间人攻击时,仍然会有数据被监听的可能性),如果选择Full(strict),那么不仅全程都SSL加密,并且Cloudflare会验证网站服务器证书,需要是受信任的证书或者由Cloudflare签署的专门用于服务器上的证书。
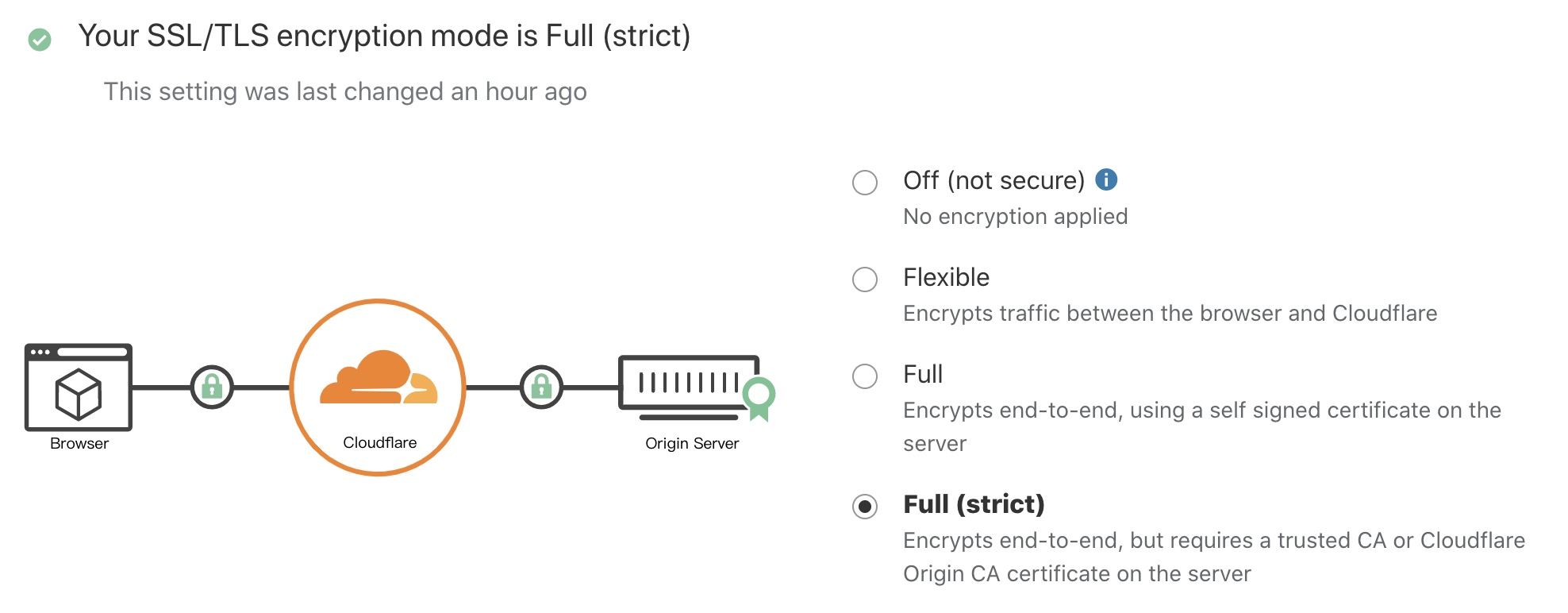
加密这一段流量非常简单,你只需要在上面的SSL设置中,选择Off以外的其他选项,即可完成这一段的SSL加密,默认情况下,免费版本的Cloudflare提供Universal SSL证书,这类证书目前基本被大多数浏览器所信任,只是在证书名称上你看到的可能是sni.cloudflare.com的域名。如果你希望提升SSL证书的兼容性,那可以在SSL/TLS下的Edge Certificates菜单中,单独订购SSL证书,独立证书5美金一个月,订购之后,您的证书就会像下图一样属于独立域名证书,兼容性也会更好,当然,如果你有钱(例如有的企业需要OV甚至EV证书),那么你可以购买Enterprise Plan后,选择上传自己的证书,只是价格么就贵了。
加密这一段流量,就需要您在Nginx上做HTTPS的配置了,一般情况下,订购一个受信任的证书总是费钱的,Cloudflare建议你使用他们的Origin CA,证书周期15年且免费,使用方法也非常简单,首先在SSL/TLS的Origin Server菜单下,选择”Create Certificate“,创建一张证书,选择Cloudflare创建CSR即可,域名和时常一般不用更改,创建之后,即可保存证书和私钥,Nginx一般使用pem格式,因此把证书和私钥保存成cert.pem和key.pem两个文件,并上传到你的服务器上。
第二步,打开你的Nginx配置,加入如下的设置(假设你的证书都储存在/usr/local/nginx/conf/ssl/目录下)
1 | listen 443 ssl http2; |
保存并重启你的Nginx服务器后,在SSL/TLS下选择Full(strict)模式,即可完成Cloudflare CDN服务器到你网站服务器之间的加密了。
Authenticated Origin Pulls保证了客户端在获取你网站服务器的内容时,需要提交客户端证书验证,否则不允许访问,这个设置通常可以进一步防止你的服务器数据被非Cloudflare CDN服务器访问,当你的源站全站采用CDN后,可以打开这个选项进一步提升安全性,在打开之前,需要在Nginx上做如下配置:
1 | ssl_client_certificate /usr/local/nginx/conf/ssl/origin-pull-ca.crt; |
当然,终极策略,我们可以考虑在Nginx上,屏蔽一切非Cloudflare CDN服务器的访问,我们可以在 https://www.cloudflare.com/ips/ 看到所有Cloudflare使用的IP,我们可以在新建一个如下的cf.conf的配置,填写如下内容:
1 | # https://www.cloudflare.com/ips |
然后,我们在Nginx的配置下,增加如下配置
1 | include cf.conf; |
这样,所有非Nginx IP访问都会被拒绝,这样的话,整个源站的保护基本已经做到比较完善的程度了。
钱是治疗情绪的最佳良药,简单,粗暴,好用。
Open Google Chrome in your computer.
1 | chrome://dino/ |
Now enter chrome://dino/ in the URL address bar and press “Enter”. Or simply disconnect your internet and try to visit any website. After performing this step you will see the Google Dinosaur/T-Rex Game.
Press “F12” on your keyboard. It will open a new window/box on your screen. You need to click the “Console” button/tab on this new window.
It’s time to add some code here.
Just copy the code given below and paste it inside the “Console” window. After that press “Enter”.
1 | function keyDown(e){Podium={};var n=document.createEvent("KeyboardEvent");Object.defineProperty(n,"keyCode",{get:function(){return this.keyCodeVal}}),n.initKeyboardEvent?n.initKeyboardEvent("keydown",!0,!0,document.defaultView,e,e,"","",!1,""):n.initKeyEvent("keydown",!0,!0,document.defaultView,!1,!1,!1,!1,e,0),n.keyCodeVal=e,document.body.dispatchEvent(n)}function keyUp(e){Podium={};var n=document.createEvent("KeyboardEvent");Object.defineProperty(n,"keyCode",{get:function(){return this.keyCodeVal}}),n.initKeyboardEvent?n.initKeyboardEvent("keyup",!0,!0,document.defaultView,e,e,"","",!1,""):n.initKeyEvent("keyup",!0,!0,document.defaultView,!1,!1,!1,!1,e,0),n.keyCodeVal=e,document.body.dispatchEvent(n)}setInterval(function(){Runner.instance_.horizon.obstacles.length>0&&(Runner.instance_.horizon.obstacles[0].xPos<25*Runner.instance_.currentSpeed-Runner.instance_.horizon.obstacles[0].width/2&&Runner.instance_.horizon.obstacles[0].yPos>75&&(keyUp(40),keyDown(38)),Runner.instance_.horizon.obstacles[0].xPos<30*Runner.instance_.currentSpeed-Runner.instance_.horizon.obstacles[0].width/2&&Runner.instance_.horizon.obstacles[0].yPos<=75&&keyDown(40))},5); |
Start the game by pressing “Space” or “Up Arrow” key.
https://www.edopedia.com/blog/javascript-code-plays-google-dinosaur-t-rex-game-automatically/
人心本無染,心靜自然清。
1 | location [ = | ~ | ~* | ^~ ] uri { ... } |
语法规则很简单,一个location关键字,后面跟着可选的修饰符,后面是要匹配的字符,花括号中是要执行的操作。
对请求的url序列化。例如,对%xx等字符进行解码,去除url中多个相连的/,解析url中的.,..等。这一步是匹配的前置工作。
location有两种表示形式,一种是使用前缀字符,一种是使用正则。如果是正则的话,前面有~或~*修饰符。
具体的匹配过程如下:
首先先检查使用前缀字符定义的location,选择最长匹配的项并记录下来。
如果找到了精确匹配的location,也就是使用了=修饰符的location,结束查找,使用它的配置。
然后按顺序查找使用正则定义的location,如果匹配则停止查找,使用它定义的配置。
如果没有匹配的正则location,则使用前面记录的最长匹配前缀字符location。
基于以上的匹配过程,我们可以得到以下两点启示:
使用正则定义的location在配置文件中出现的顺序很重要。因为找到第一个匹配的正则后,查找就停止了,后面定义的正则就是再匹配也没有机会了。
使用精确匹配可以提高查找的速度。例如经常请求/的话,可以使用=来定义location。
1 | location = / { |
请求/精准匹配A,不再往下查找。
请求/index.html匹配B。首先查找匹配的前缀字符,找到最长匹配是配置B,接着又按照顺序查找匹配的正则。结果没有找到,因此使用先前标记的最长匹配,即配置B。
请求/user/index.html匹配C。首先找到最长匹配C,由于后面没有匹配的正则,所以使用最长匹配C。
请求/user/1.jpg匹配E。首先进行前缀字符的查找,找到最长匹配项C,继续进行正则查找,找到匹配项E。因此使用E。
请求/images/1.jpg匹配D。首先进行前缀字符的查找,找到最长匹配D。但是,特殊的是它使用了^~修饰符,不再进行接下来的正则的匹配查找,因此使用D。这里,如果没有前面的修饰符,其实最终的匹配是E。大家可以想一想为什么。
请求/documents/about.html匹配B。因为B表示任何以/开头的URL都匹配。在上面的配置中,只有B能满足,所以匹配B。
@用来定义一个命名location。主要用于内部重定向,不能用来处理正常的请求。其用法如下:
1 | location / { |
上例中,当尝试访问url找不到对应的文件就重定向到我们自定义的命名location(此处为custom)。
值得注意的是,命名location中不能再嵌套其它的命名location。
心有猛虎,细嗅蔷薇。
1 | nginx -V |
https://www.cloudflare.com/ips/
1 | vi /etc/nginx/cloudflare; |
Open “/etc/nginx/nginx.conf” file with your favorite text editor and just add the following lines to your nginx.conf inside http{….} block.
1 |
|
1 | nginx -s reload |
做你害怕做的事情。
「Hotlink Protection」(直接連結保護)是經營網站經常需要去注意的一塊,但為什麼我們會需要「Hotlink Protection」呢?身為圖文並茂的網路文章作家,最擔心得就是自己的文章被別人整篇連文帶圖地複製貼上到其它地方了。此時如果圖片有套用「Hotlink Protection」的話,就可以讓被盜用的圖片在其它網站上「不被正常顯示」出來,如此一來,就能使其它誤入盜文頁面的訪客可以知道該篇文章是篇被盜用的文章。不同的網站架構有不同的「Hotlink Protection」的設定方式,如果您的網站是使用Nginx伺服器來架設的話,可以參考這篇文章,來實現「Hotlink Protection」的功能。
「ngx_http_referer_module」是Nginx預設啟用的模組,可以用來阻擋使用無效HTTP標頭的Referer欄位的請求。使用「ngx_http_referer_module」模組時,通常會在Nginx設定檔中的特定location區塊內撰寫「valid_referers」命令,來針對特定連結做檢查HTTP標頭中Referer欄位的動作。
例如:
1 | location ~ \.(jpg|jpeg|png|gif)$ { |
先從location ~ \.(jpg|jpeg|png|gif)$開始介紹起。撰寫於server區塊內的location區塊,可以使Nginx伺服器能針對特定格式的網址來做不同的動作。至於這個「特定格式的網址」的網址規則,則是直接接在location這個命令之後。此處的~,表示要使用正規表示式,且必須判斷大小寫(case-sensitive)。而\.(jpg|jpeg|png|gif)$這串正規表示式,則代表所有以.jpg、.jpeg、.png或.gif結尾的網址。您可以將需要加上「Hotlink Protection」的圖片副檔名都放進這個正規表示式內。
再來看一下valid_referers命令,valid_referers命令可以用來設定$invalid_referer變數的值。若請求中的HTTP標頭的Referer欄位有符合valid_referers命令所指定的條件,此時$invalid_referer變數的值為空字串,所以之後的if判斷式就不會成立;若Referer欄位不符合valid_referers命令所指定的條件,則此時$invalid_referer變數的值為1,所以之後的if判斷式就會成立,而使得該連結會直接回傳HTTP的403狀態(Forbidden)。
至於valid_referers命令所接受的參數,有以下幾個:
(*),表示任意數量的任意字元。~字元為開頭再接上正規表示式,來判斷請求HTTP標頭中的Referer欄位值是否符合指定的正規表示式。如果想要將無效的請求轉到其它網址,需要修改return命令,可以參考以下連結:
https://magiclen.org/nginx-rewrite
如果網站有使用CDN的話,本篇文章的作法就不怎麼合適了。若是Cloudflare CDN的話,可以參考以下連結來設定:
https://magiclen.org/cloudflare-hotlink-protection/
“你只见到这么多人说他不好时, 却看到他有出来说別人一句吗?”
MutationObserver 是一个内建对象,它观察 DOM 元素,在其发生更改时触发回调。
我们将首先看一下语法,然后探究一个实际的用例,以了解它在什么地方有用。
MutationObserver 使用简单。
首先,我们创建一个带有回调函数的观察器:
1 | let observer = new MutationObserver(callback); |
然后将其附加到一个 DOM 节点:
1 | observer.observe(node, config); |
config 是一个具有布尔选项的对象,该布尔选项表示“将对哪些更改做出反应”:
其他几个选项:
MutationRecord 对象具有以下属性:
type —— 变动类型,以下类型之一:
“attributes”:特性被修改了,
“characterData”:数据被修改了,用于文本节点,
“childList”:添加/删除了子元素。
target —— 更改发生在何处:”attributes” 所在的元素,或 “characterData” 所在的文本节点,或 “childList” 变动所在的元素,
addedNodes/removedNodes —— 添加/删除的节点,
previousSibling/nextSibling —— 添加/删除的节点的上一个/下一个兄弟节点,
attributeName/attributeNamespace —— 被更改的特性的名称/命名空间(用于 XML),
oldValue —— 之前的值,仅适用于特性或文本更改,如果设置了相应选项 attributeOldValue/characterDataOldValue。
例如,这里有一个
contentEditable 特性。该特性使我们可以聚焦和编辑元素。
1 | <div contentEditable id="elem">Click and <b>edit</b>, please</div> |
如果我们在浏览器中运行上面这段代码,并聚焦到给定的 <div> 上,然后更改 <b>edit</b> 中的文本,console.log 将显示一个变动:
1 | mutationRecords = [{ |
如果我们进行更复杂的编辑操作,例如删除 edit,那么变动事件可能会包含多个变动记录:
1 | mutationRecords = [{ |
因此,MutationObserver 允许对 DOM 子树中的任何更改作出反应。
在什么时候可能有用?
想象一下,你需要添加一个第三方脚本,该脚本不仅包含有用的功能,还会执行一些我们不想要的操作,例如显示广告 <div class="ads">Unwanted ads</div>。
当然,第三方脚本没有提供删除它的机制。
使用 MutationObserver,我们可以监测到我们不需要的元素何时出现在我们的 DOM 中,并将其删除。
还有一些其他情况,例如第三方脚本会将某些内容添加到我们的文档中,并且我们希望检测出这种情况何时发生,以调整页面,动态调整某些内容的大小等。
MutationObserver 使我们能够实现这种需求。
从架构的角度来看,在某些情况下,MutationObserver 有不错的作用。
假设我们正在建立一个有关编程的网站。自然地,文章和其他材料中可能包含源代码段。
在HTML 标记(markup)中的此类片段如下所示:
1 | ... |
另外,我们还将在网站上使用 JavaScript 高亮显示库,例如 Prism.js。调用 Prism.highlightElem(pre) 会检查此类 pre 元素的内容,并在其中添加特殊标签(tag)和样式,以进行彩色语法高亮显示,类似于你在本文的示例中看到的那样。
那什么时候运行该高亮显示方法呢?我们可以在 DOMContentLoaded 事件中或者在页面尾部运行。到那时,我们的 DOM 已准备就绪,我们可以搜索元素 pre[class*="language"] 并对其调用 Prism.highlightElem:
1 | // 高亮显示页面上的所有代码段 |
到目前为止,一切都很简单,对吧?HTML 中有 <pre> 代码段,我们高亮显示它们。
现在让我们继续。假设我们要从服务器动态获取资料。我们将 在本教程的后续章节 中学习进行此操作的方法。目前,只需要关心我们从网络服务器获取 HTML 文章并按需显示
1 | let article = /* 从服务器获取新内容 */ |
新的 article HTML 可能包含代码段。我们需要对其调用 Prism.highlightElem,否则它们将不会被高亮显示。
对于动态加载的文章,应该在何处何时调用 Prism.highlightElem?
我们可以将该调用附加到加载文章的代码中,如下所示:
1 | let article = /* 从服务器获取新内容 */ |
……但是,想象一下,代码中有很多地方可以加载内容:文章,测验,论坛帖子。我们是否需要在每个地方都附加一个高亮显示调用?那不太方便,也很容易忘记。
并且,如果内容是由第三方模块加载的,该怎么办?例如,我们有一个由其他人编写的论坛,该论坛可以动态加载内容,并且我们想为其添加语法高亮显示。没有人喜欢修补第三方脚本。
幸运的是,还有另一种选择。
我们可以使用 MutationObserver 来自动检测何时在页面中插入了代码段,并高亮显示之它们。
因此,我们在一个地方处理高亮显示功能,从而使我们无需集成它。
1 | let observer = new MutationObserver(mutations => { |
下面有一个 HTML 元素,以及使用 innerHTML 动态填充它的 JavaScript。
请先运行前面那段代码(上面那段,观察元素),然后运行下面这段代码。你将看到 MutationObserver 是如何检测并高亮显示代码段的。
一个具有 id=”highlight-demo” 的示例元素,运行上面那段代码来观察它。
下面这段代码填充了其 innerHTML,这导致 MutationObserver 作出反应,并突出显示其内容:
1 | let demoElem = document.getElementById('highlight-demo'); |
现在我们有了 MutationObserver,它可以跟踪观察到的元素中的,或者整个 document 中的所有高亮显示。我们可以在 HTML 中添加/删除代码段,而无需考虑高亮问题。