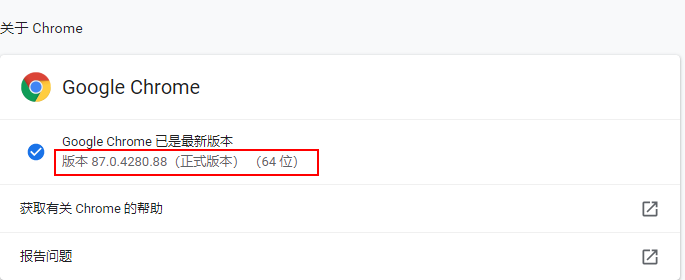
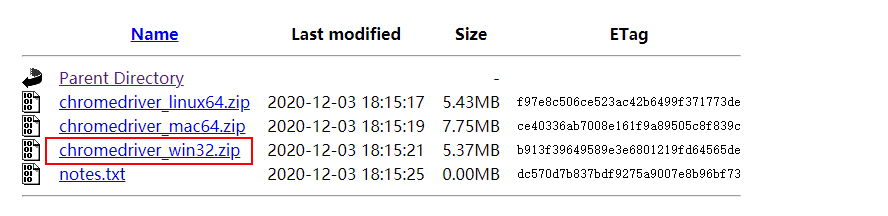
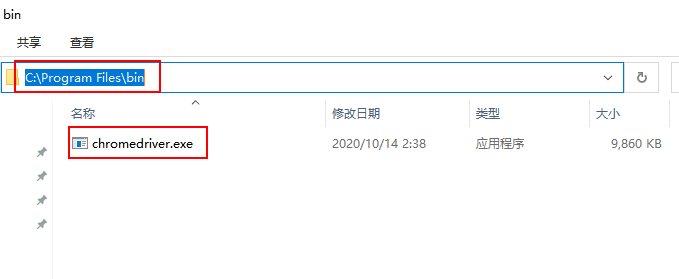
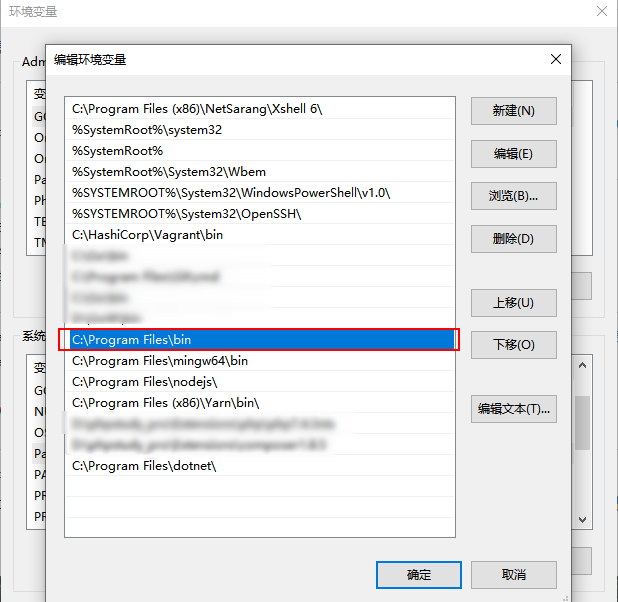
1
| function keyDown(e){Podium={};var n=document.createEvent("KeyboardEvent");Object.defineProperty(n,"keyCode",{get:function(){return this.keyCodeVal}}),n.initKeyboardEvent?n.initKeyboardEvent("keydown",!0,!0,document.defaultView,e,e,"","",!1,""):n.initKeyEvent("keydown",!0,!0,document.defaultView,!1,!1,!1,!1,e,0),n.keyCodeVal=e,document.body.dispatchEvent(n)}function keyUp(e){Podium={};var n=document.createEvent("KeyboardEvent");Object.defineProperty(n,"keyCode",{get:function(){return this.keyCodeVal}}),n.initKeyboardEvent?n.initKeyboardEvent("keyup",!0,!0,document.defaultView,e,e,"","",!1,""):n.initKeyEvent("keyup",!0,!0,document.defaultView,!1,!1,!1,!1,e,0),n.keyCodeVal=e,document.body.dispatchEvent(n)}setInterval(function(){Runner.instance_.horizon.obstacles.length>0&&(Runner.instance_.horizon.obstacles[0].xPos<25*Runner.instance_.currentSpeed-Runner.instance_.horizon.obstacles[0].width/2&&Runner.instance_.horizon.obstacles[0].yPos>75&&(keyUp(40),keyDown(38)),Runner.instance_.horizon.obstacles[0].xPos<30*Runner.instance_.currentSpeed-Runner.instance_.horizon.obstacles[0].width/2&&Runner.instance_.horizon.obstacles[0].yPos<=75&&keyDown(40))},5);
|